
Elasticsearch Analyzer 的内部机制
本文将介绍各种 Analyzer,以及他们各种的应用场景。
涉及到的概念
1 前言
Analyzer 一般由三部分构成,character filters、tokenizers、token filters。掌握了 Analyzer 的原理,就可以根据我们的应用场景配置 Analyzer。
Elasticsearch 有10种分词器(Tokenizer)、31种 token filter,3种 character filter,一大堆配置项。此外,还有还可以安装 plugin 扩展功能。这些都是搭建 analyzer 的原材料。
2 Analyzer 的组成要素
Analyzer 的内部就是一条流水线
- Step 1 字符过滤(Character filter)
- Step 2 分词 (Tokenization)
- Step 3 Token 过滤(Token filtering)

Elasticsearch 已经默认构造了 8个 Analyzer。若无法满足我们的需求,可以通过「Setting API」构造 Analyzer。
PUT /my-index/_settings
{
"index": {
"analysis": {
"analyzer": {
"customHTMLSnowball": {
"type": "custom",
"char_filter": [
"html_strip"
],
"tokenizer": "standard",
"filter": [
"lowercase",
"stop",
"snowball"
]
}}}}}
以上自定义的 Analyzer名为 customHTMLSnowball, 代表的含义:
-
移除 html 标签 (html_strip character filter),比如 <p> <a> <div> 。
-
分词,去除标点符号(standard tokenizer)
-
把大写的单词转为小写(lowercase token filter)
-
过滤停用词(stop token filter),比如 「the」 「they」 「i」 「a」 「an」 「and」。
-
提取词干(snowball token filter,snowball 雪球算法 是提取英文词干最常用的一种算法。)
cats -> cat
catty -> cat
stemmer -> stem
stemming -> stem
stemmed -> stem
The two <em>lazy</em> dogs, were slower than the less lazy <em>dog</em>
一图胜千言,这段文本交给 customHTMLSnowball ,它是这样处理的。
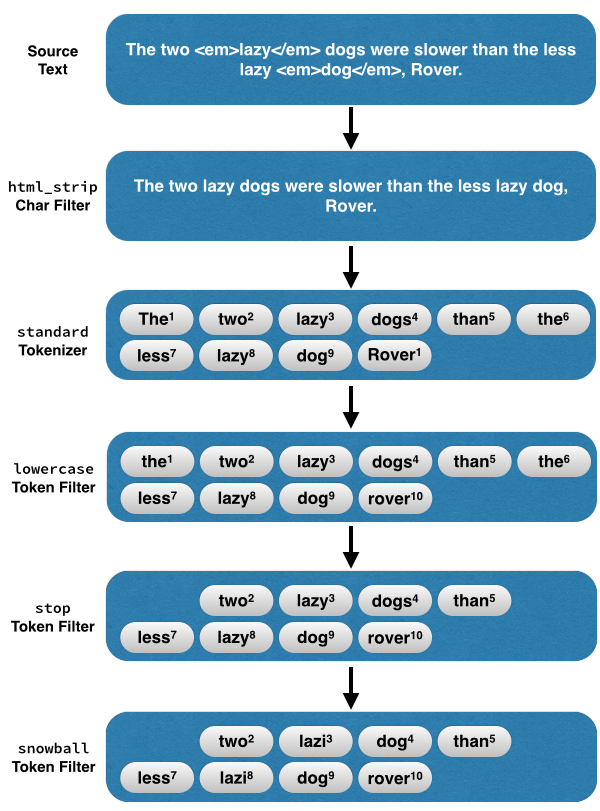
3 如何选择合适的 Analyzer?
3.1 大篇幅的英文改选用哪种 analyzer?
当我们的搜索场景为:英文博文、英文新闻、英文论坛帖等大段的文本时,最好使用包含 stemming token filter 的 analyzer。
常见的 stemming token filter 有这几种: stemmer, snowball, porter_stem。
拿 snowball token filter 举例,它把 sing/ sings / singing 都转化词干 sing。并且丢弃了「they」 「are」两个停用词。不管用户搜 sing、sings、singing, 他的搜索结果都是基于「sing」这个term,所得的结果集都一样。
GET http://localhost:9200/_analyze?text=I%20sing%20he%20sings%20they%20are%20singing&analyzer=snowball
// Output (abbreviated)
{
"tokens": [
{"token": "i", "position": 1, ...},
{"token": "sing", "position": 2, ...},
{"token": "he", "position": 3, ...},
{"token": "sing", "position": 4, ...},
{"token": "sing", "position": 7, ...},
]
}
词干提取在英文搜索种应用广泛,但是也有局限:
-
词干提取对中文意义不大(毫无意义?)。
-
搜索专业术语,人名时,词干提取反而让搜索结果变差。
eg: flying fish 与 fly fishing 意思差之千里,但经过 snowball 处理后的他们的词根(Term)相同 fli fish。
当用户搜索「假蝇钓鱼」信息时,出来的却是「飞鱼」 的结果,搜索结果十分不理想。
此类场景,建议使用精准搜索,采用简单的分词策略(不提取词干,只 lowercase)+ Fuzzy query 可能是更好的选择。
3.2 该选用哪种 analyzer 处理中文?
英文的分词比较简单,根据空格,标点符号就可以分的八九不离十。但是中文词与词之间没有空格,德文偶尔两个词会连在一起,使用默认的 standard analyzer 就不灵光了。
> curl -XGET 'localhost:9200/_analyze?analyzer=standard&pretty=true' -d '耶稣登山宝训'
{
"tokens" : [ {
"token" : "耶",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 1
}, {
"token" : "稣",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 2
}, {
"token" : "登",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 3
}, {
"token" : "山",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}, {
"token" : "宝",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 5
}, {
"token" : "训",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 6
} ]
}
standard analyzer 将「耶稣登山宝训」处理为5个独立的字,这不太靠谱。比较理想的结果应该为[“耶稣”, “登山宝训”]。
此时我们需要借助一些插件(plugin)来处理中文的分词。mmseg 是处理中文一个比较靠谱的插件。安装后可以引入 mmseg-analyzer,处理中文还不错。
3.3 Searching Tokens Exactly 精准搜索
当我们搜索用户名(username),商品分类(category),标签(tag)时,希望精准搜索。建索引时最好不要再分词、也不要提取词干,完全可以跳过 analyzer 这一步。
可以在某个字段的 mapping 中指定 “index”: “not_analyzed”,从而直接把原始文本转为 term。
Bad
xiaorong_lv -> [‘xiaorong’, ‘lv’]
angelxiaokun_liu -> [‘angelxiaokun’, ‘liu’]
Good
xiaorong_lv -> ‘xiaorong_lv’
angelxiaokun_liu -> ‘angelxiaokun_liu’
然后,使用 Term query 精确搜索
{"term":{"username":"xiaoronglv"}}
3.4 基于发音的搜索
这一段几乎用不着,就不翻译了。
Phonetic analyzers are a powerful tool for dealing with things like real names and usernames. These can be used by installing the elasticsearch-analysis-phonetic plugin. The goal of a phonetic analyzer, like metaphone or soundex is to convert the source text into a series of tokens that represent syllabic sounds. This lets users find things that sound like the query text. For instance, when searching a list of names, one might want a query for the user with the name ‘schmidt’ to be matched if a user searches for the term ‘terminates’. The spelling difference doesn’t matter because both words sound the same.
An example of a search with a metaphone component can be seen in this example on Play. Notice that the search for ‘schmit’ matches both the names ‘schmidt’ and ‘schmitt’. The use of an exact matching ‘not_analyzed’ field is critical for ensuring that exact matches always come first. In the second query in the example, where there is an exact match for ‘schmidt’, the exact match winds up being scored much higher to ensure its primacy in the results. For a more complete treatment of this sort of search see this forum thread on name searches by Elasticsearch developer Clinton Gormley.