
Feed 流设计(二):拉模式 Vs 推模式
Feed 后台设计文章索引
在上一篇文章中,我们谈到「如何用事件抽象Feed中多态的内容」,这篇文章会进一步讨论事件的分发问题。
当用户分享一个视频时,该视频应该出现在他 Follower 的 Feed流中。比如Ryan和 Sam 是 facebook 好友,Ryan更新状态「我今天感觉好极了」。Sam 登录 facebook 时,会在自己的 feed 流中看到Ryan的状态更新。
如何实现?通常有拉和推二种做法。
方式一:拉模式
Sam 有7个 facebook 好友,每次 Sam 登录,只需要遍历所有好友的产生的 event,按时间逆序排列即可。
step1: 查询 Sam 朋友的主键 ID
select friend_id from friendships where user_id = 3
=> [1, 4, 8, 10, 33, 78, 101]
step2: 在上一篇文章中,我们用 event 来抽象 feed 流中的内容,并且保存在 table events 中。根据好友的主键 ID 过滤 event,并且渲染给 Sam 即可。
select * from events where user_id in [1, 4, 8, 10, 33, 78, 101] order by id desc
优点
-
实现简单,可以应对基本需求,比如关注,屏蔽,取消关注,取消屏蔽。
-
假装关注:虽然我关注你了,但是我压根不想在feed中看到你。如果用拉的模式,sql 要写成这个样子
-
屏蔽:虽然我们互相关注了,但是我屏蔽了你的动态,不想在feed中看到你。
step1: 拉取 Sam 的好友,剔除假装关注/屏蔽的好友
// is_faked: 假装关注 // is_blocked: 屏蔽 select friend_id from friendships where user_id = 3 and is_faked = 0 and is_blocked = 0 [1, 4, 8, 10]step2: 拉取 Sam 好朋友产生的 Feed 内容。
select * from events where user_id in [1, 4, 8, 10] order by id desc -
- 关注/取消关注后,feed 中的内容会动态变化,易于维护。
- 与「推模式」相比,没有冗余数据,不占用存储空间。
缺点
首先,当 Sam 有1000个好友时,即使有索引,获取 SQL语句的执行效率会变低。
select * from events where user_id in [1, 4, 8, 10, 33, 78, 101, ... , 1001] order by id desc
其次,无法应对企业应用中复杂且严格的权限检查。
我拿我们产品中的场景举例,部门经理 Bob 在私密的小组「人事管理」中创建了文档 「2019年薪酬调整方案」。
Bob 的这个操作,到底该出现在 Sam 的 Feed 流中吗? 由以下几个因素决定
-
Sam 有这个 Group 的访问权限吗?
权限信息有可能通过 rpc 获取,也有可能在非关系型数据库中。 e.g. Redis
-
即使 Sam 已经获得授权,也必须先接受使用条款(Term of Use),否则不能访问小组中的内容。
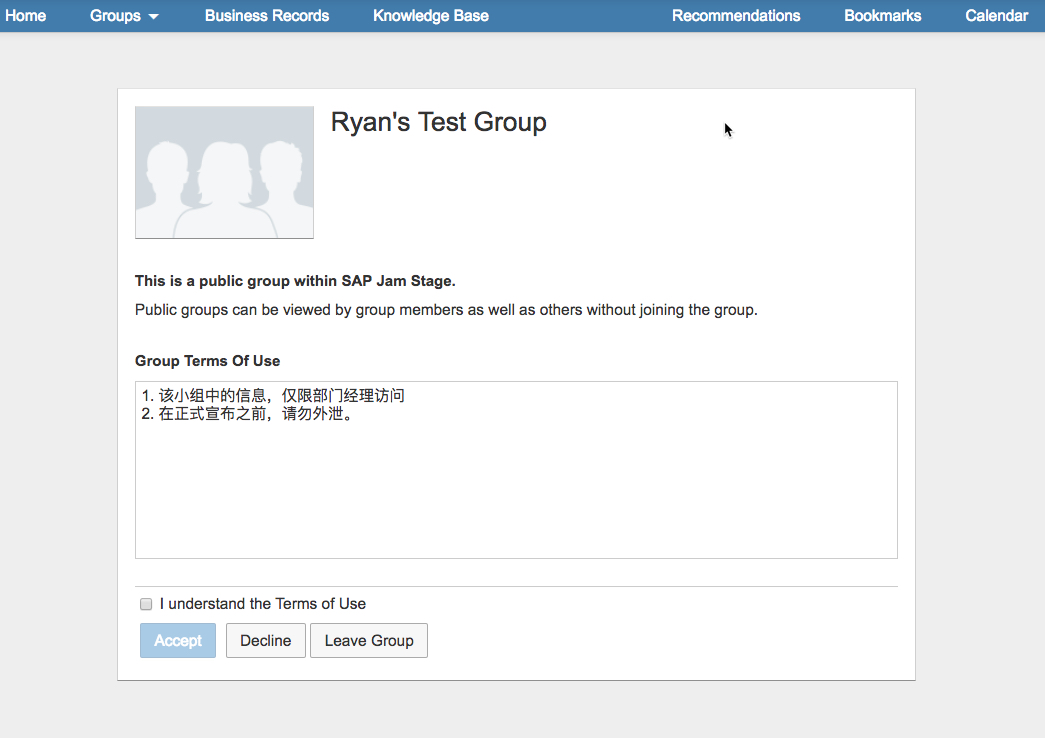
-
Sam 有没有屏蔽了该小组的动态?
如果用 sql 来构造,可能要这样写,但是有些条件可能存在 Redis 中,无论如何也是写不出来的。
select * from events join groups on something join group_memberships on something join term_of_uses on something where user_id in [1, 4, 8, 10, 33, 78, 101] and condition1: sam can access this group condition2: sam accepted term of use condition3: sam doesn't block this group order by id desc
方式二:推模式。
- 每个用户拥有自己的队列,在自己的队列中读取 feed 流信息。
- 新的 feed 产生时,写到 followers 的队列中。写入前,检查各种规则,如果不满足条件,就不写入。
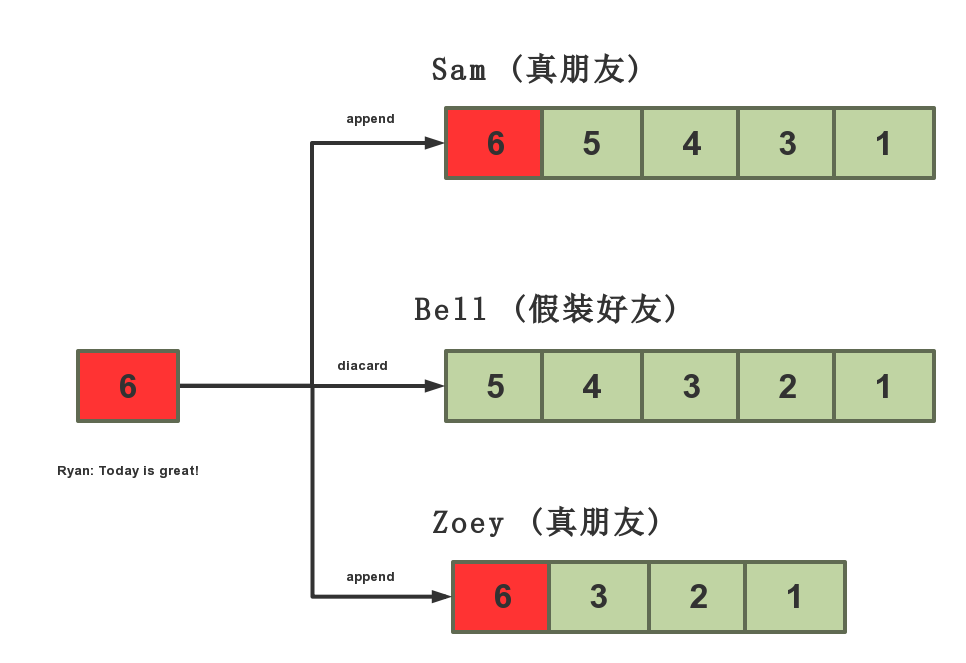
比如 Ryan 在 facebook 有三个朋友 Sam,Bell,Zoey, Bell 嫌弃 Ryan 话多,偷偷屏蔽了Ryan。
当 Ryan 发布了一条动态 「Today is great!」(红颜色6),系统应当只分发该动态至 Sam 和 Zoey 的队列。因为 Bell 屏蔽了 Ryan,所以 Ryan 的更新并不会分至 Bell 的队列。
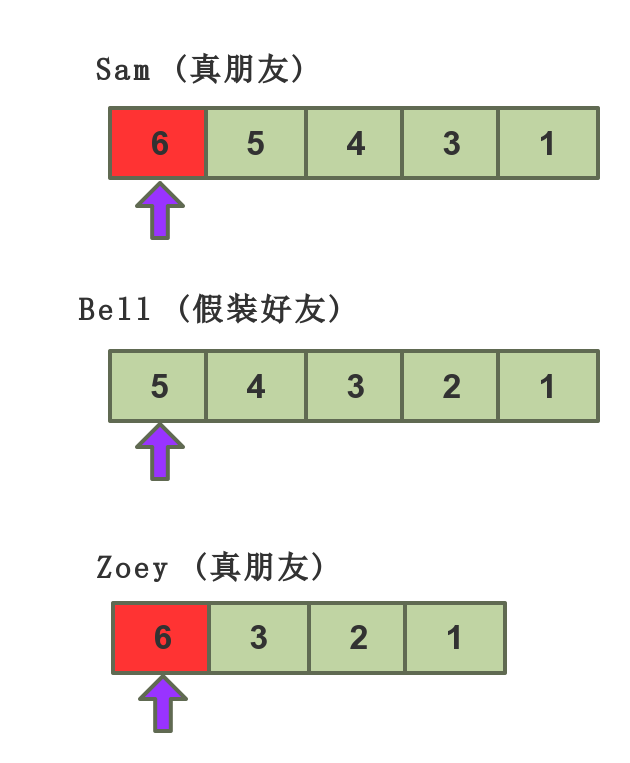
下次 Sam/Zoey登录时,会在自己的队列中看到 Ryan 的动态更新 6;Bell登录时,则不会看到 6。
优点
- 读的性能高。
- 可以覆盖各种各样的业务场景。
缺点
- 需要大量的写入,尤其是当某个用户有100万的 follower 时,写入会非常耗时,需要额外的优化。
- 当用户的关注/取消关注时,要更新队列,剔除已经失效的 feed 内容。
- 常年不登录的僵尸用户的队列,会占用大量的存储空间,如果存储层是内存型数据库,每个月的花费不菲[1]。
推模式可以灵活应对各种业务场景
随着产品的发展,会出现各种各样的商业场景和 feed 流相关。
-
公司拥有自己的 feed 主页。 (CompanyFeed)
e.g. SAP 的facebook 主页 -
热门的 tag 会有自己的 feed 主页,用户可以关注标签。 (TagFeed)
e.g. facebook RocksDB 的 tag页面 -
一本书/股票/电影/工作机会/线下聚会也会有自己的 feed 主页 (ObjectFeed)
-
一个人会有自己的 public feed 主页。(ProfileFeed)
e.g. Ryan的facebook主页 -
一个兴趣小组会有自己的 feed 主页。 (GroupFeed)
-
一个人会有特别好友,他有时只想看特别好友的更新。 (CloseFriendFeed)
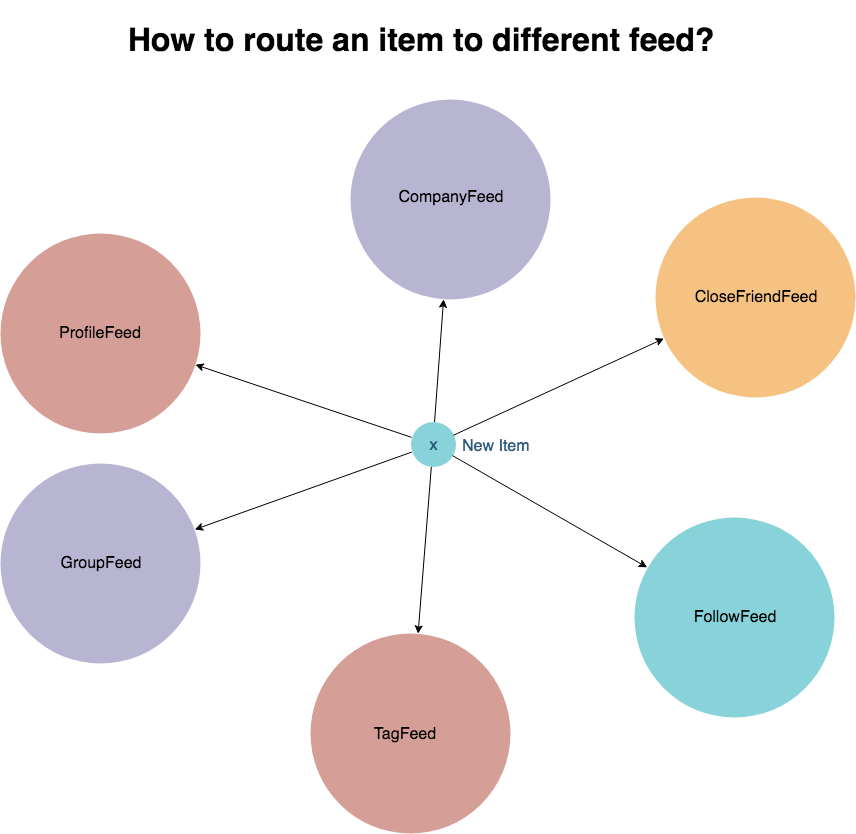
理论上讲,当 Ryan 在兴趣小组 RocksDB Developers Public 更新一条带标签的动态 “#RocksDB is great!” 时,
这条内容应该出现在 ②, ④, ⑤,⑥ 四个地方:tag RocksDB 的feed 主页;Ryan 的个人主页;兴趣小组 RocksDB Developers Public 的主页;Ryan 密友的主页。

推模式下,各个组件如何协作?
推模式可以将分发逻辑写在代码里,而不是查询语句里。然后根据逻辑将新的动态(feed_event)分发至符合条件队列里,满足各种各样的业务需求。受众只需要在相应的队列里读取数据即可,查询语句十分简洁,读取效率高。
备注
1.如何应对僵尸用户?
几年前我在薄荷网工作,那时有2000万用户,但日活只有20+万。换句话说,存在大量的僵尸用户。如果为他们准备好队列,填满内容,其实是很不划算的,浪费了大量的存储空间。尤其是使用内存数据库时,简直是烧钱。当时采用的策略是:平时不管这些僵尸用户,他们的队列是空的,没有任何 feed,当他们登录时,临时去拉数据,把他们的队列填满。
但是企业市场不能这么考虑问题,SAP 的客户每年都在付费,人家买的就是服务。所以即使客户不登录,我们还是把每个客户队列中的内容准备好。
下一篇文章,我们来聊如何分发事件到各个队列。